That may be the intention, but you shouldn’t rely on it. In practice the average IO size is, or at least was, almost always 4KB.
Here’s a screenshot from atop while the task was running: <https://db48x.net/temp/Screenshot%20from%202019-11-19%2023-4...>. Note the number of page faults, the swin and swout (swap in and swap out) numbers, and the disk activity on nvme0n1. Swap in is 150k, and the number of disk reads was 116k with an average size of 6KB. Swap out was 150k with 150k disk writes of 4KB. It’s also reading from sdh at a fair clip (though not as fast as I wanted!)
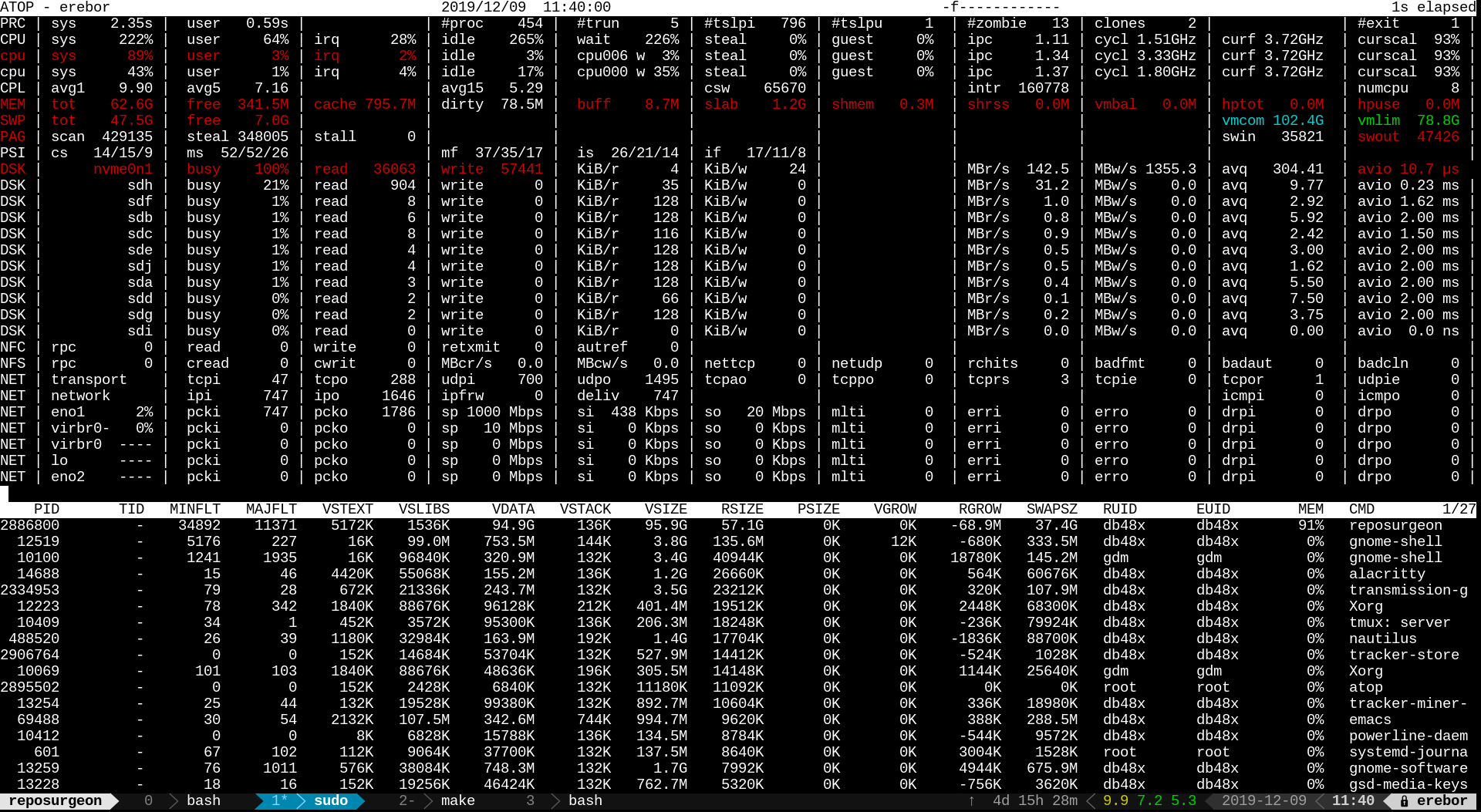
<https://db48x.net/temp/Screenshot%20from%202019-12-09%2011-4...> is interesting because it actually shows 24KB average write size. But notice that swout is 47k but there were actually 57k writes. That’s because the program I was testing had to write data out to disk to be useful, and I had it going to a different partition on the same nvme disk. Notice the high queue depth; this was a very large serial write. The swap activity was still all 4KB random IO.
That's surprising. Do you know what your application memory access pattern is like, is it really this random and the single page io is working along its grain, or is the page clustering, io readahead etc just MIA?
I didn’t delve very deep into it, but the program was written in Go. At this point in the lifecycle of the program we had optimized it quite a bit, removing all the inefficiencies that we could. It was now spending around two thirds of its cpu cycles on garbage collection. It had this ridiculously large heap that was still growing, but hardly any of it was actually garbage.
I rewrote a slice of the program in Rust with quite promising results, but by that time there wasn’t really any demand left. You see, one of the many uses of Reposurgeon <http://www.catb.org/esr/reposurgeon/> is to convert SVN repositories into Git repositories. These performance results were taken while reposurgeon was running on a dump of the GCC source code repository. At the time this was the single largest open source SVN repository left in the world with 287k commits. Now that it’s been converted to a Git repository it’s unlikely that future Reposurgeon users will have the same problem.
Also, someone pointed out that MG-LRU <https://docs.kernel.org/admin-guide/mm/multigen_lru.html> might help by increasing the block size of the reads and writes. It was introduced a year or more after I took these screenshots, so I can’t easily verify that.
{kind=link}
{kind=link}
The free memory won't go below a configurable percentage and the contiguous io algorithms of the swap code and i/o stack can still do their work.